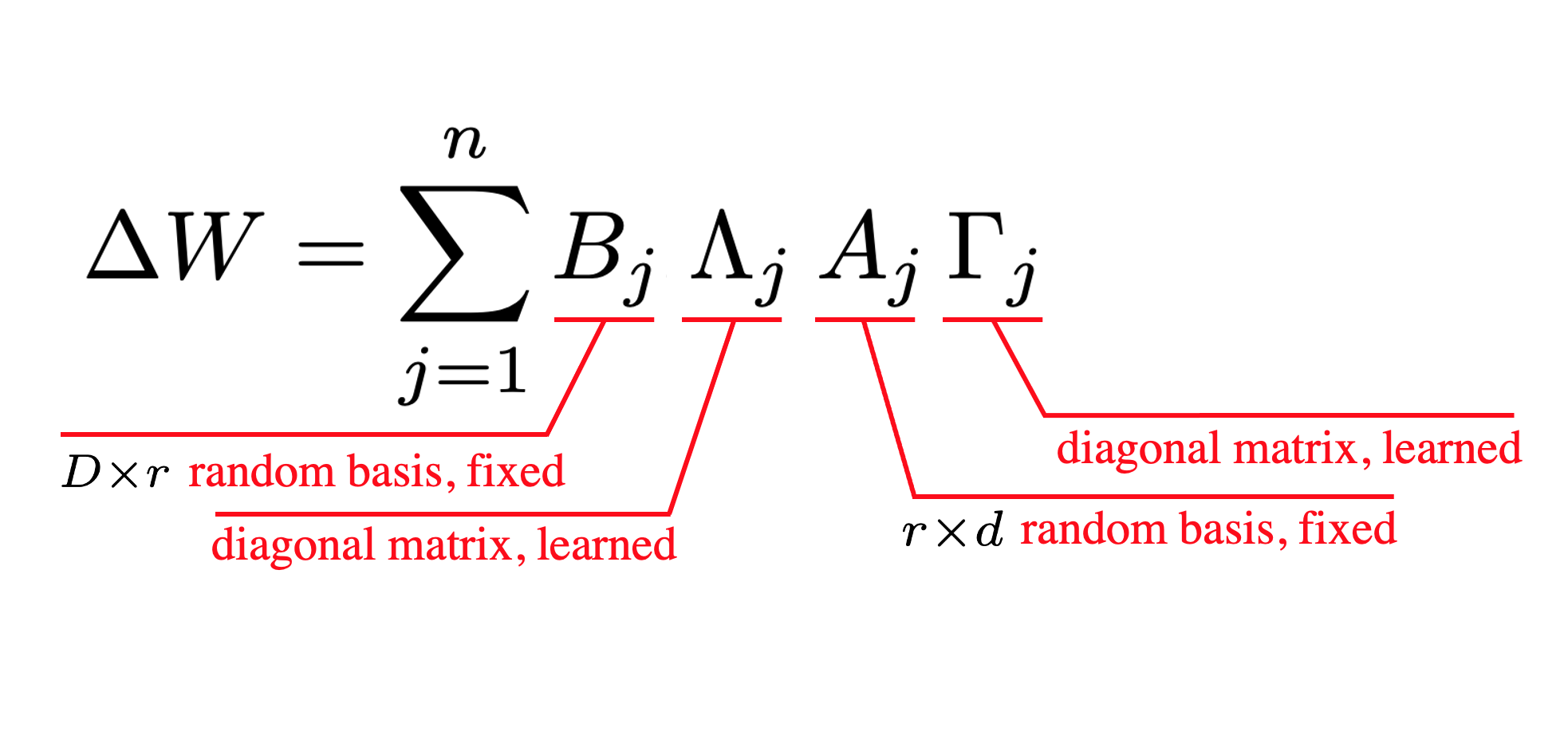
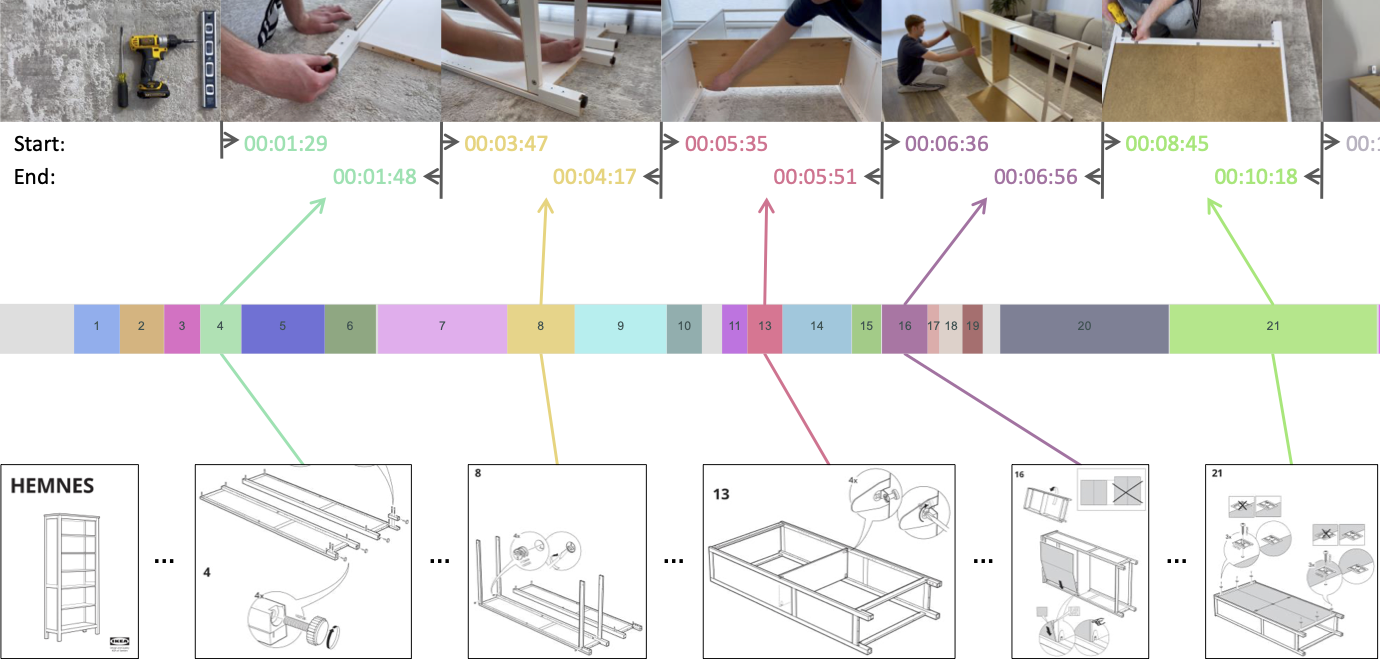
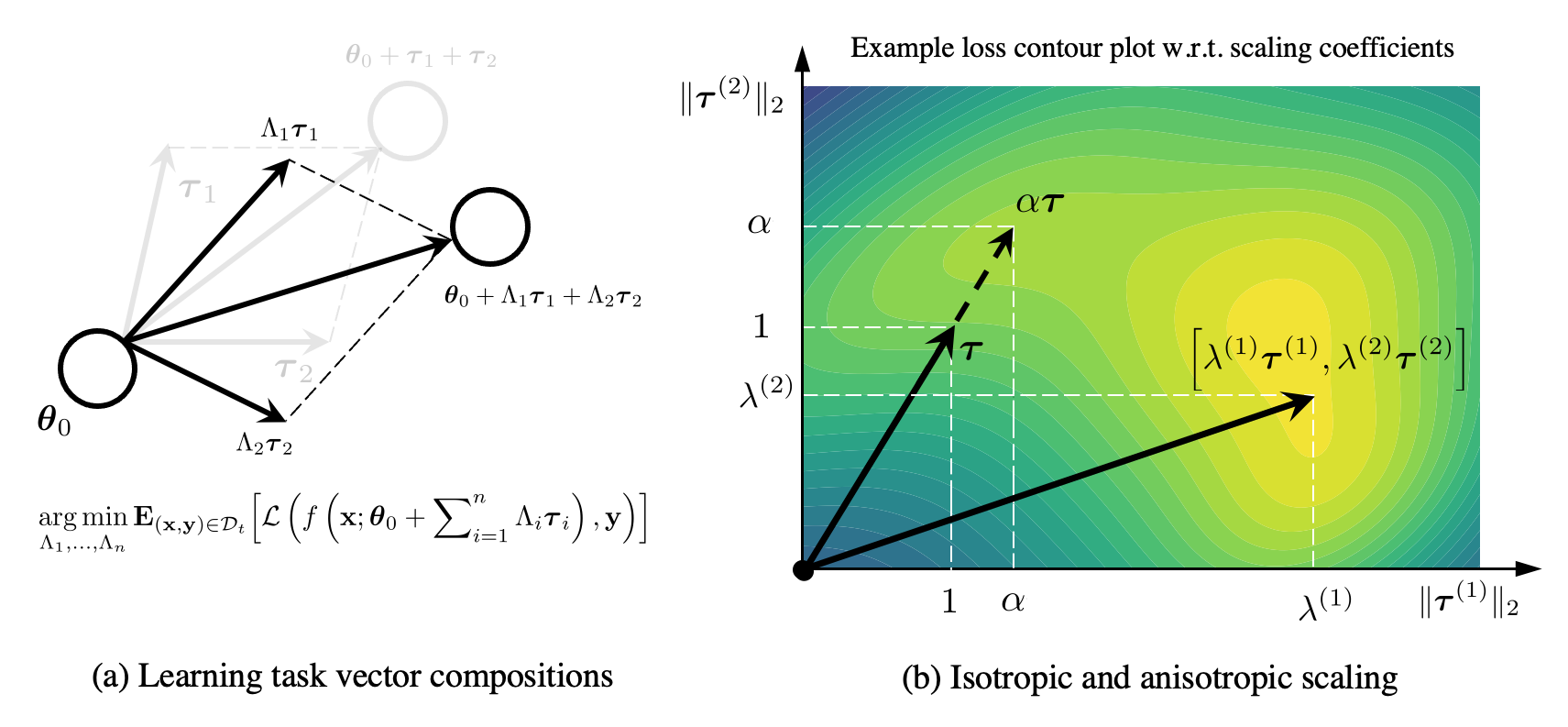
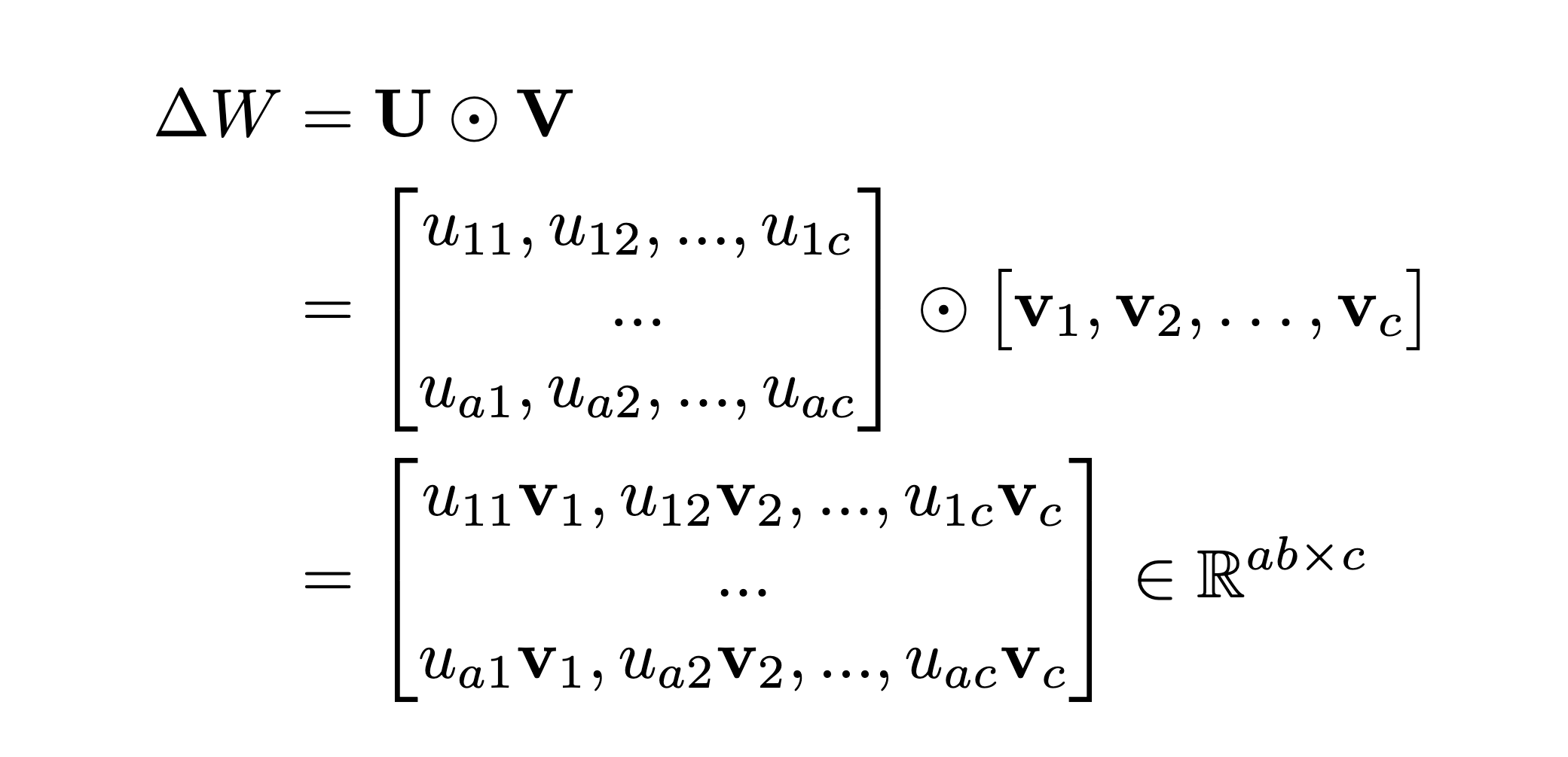Visual and Spatial Understanding of Human–Object Interactions
Frederic Z. Zhang
PhD Thesis, The Australian National University, 2024.
[abstract]
[thesis]
[bibtex]
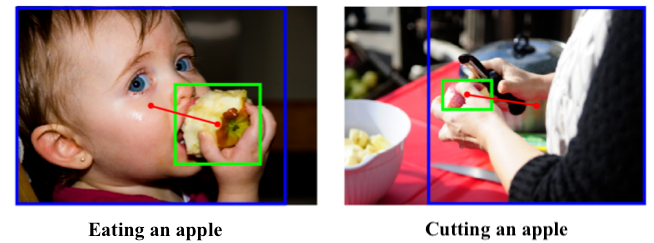
In the context of computer vision, human-object interactions (HOIs) are often characterised as a (subject, predicate, object) triplet, with humans being the subject. As such, to understand HOIs is to localise pairs of interactive instances and recognise the predicates that signify their interactions.
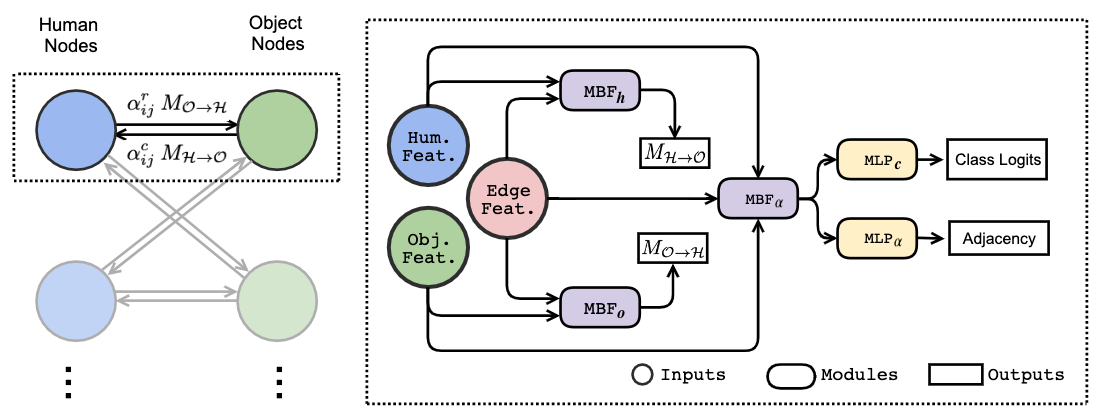
This interpretation naturally leads to a graph structure, where humans and objects are represented as nodes while their interactions as edges. We investigate this idea by employing off-the-shelf object detectors to obtain a set of human and object detections, and building a bipartite graph with human nodes on one side of the bipartition and object nodes on the other. Unlike conventional methods, wherein nodes send scaled but otherwise identical messages to each of their neighbours, we propose to condition the message passing between pairs of nodes on their spatial relationships. With spatial conditioning, the proposed method is able to suppress numerous negative pairs due to incompatible spatial relationships, and particularly excels at inferring the correspondence between interactive humans and objects when there are many pairs in the same scene. In addition, we observe that the learned adjacency matrices spontaneously exhibit structures indicative of interactive pairs without explicit supervision.
Such emergent properties prompt us to investigate further into the formulation of graphs. Apart from the unary representations (human and object instances), we incorporate human–object pairs into the graph structure by encoding each pair as a node. Utilising the popular transformer architecture, we propose the unary--pairwise transformer, wherein self-attention blocks serve as fully-connected graphs. We observe that when separate self-attention blocks are employed for the unary and pairwise representations, they specialise in complimentary ways.
Specifically, the unary layer preferentially increases the scores of positive human–object pairs, while the pairwise layer decreases the scores of negative pairs.
Despite the success in graphical modelling of HOIs, their complexity and ambiguity still poses a challenge. Through extensive visualisations, we observe that the commonly used object features are often extracted from object extremities, thus lacking the fine-grained contexts to disambiguate certain interactions. In particular, we identify two types of visual contexts lacking in current feature formulations and propose to enrich the representations with spatially-guided cross-attention, where a carefully designed box-pair positional embeddings serve as spatial biases.
With rich visualisations, we demonstrate how the spatial guidance impacts the attention mechanism and supplements the model with key visual cues for the recognition of HOIs.
@phdthesis{zhang2024thesis,
title = {Visual and Spatial Understanding of Human–Object Interactions},
author = {Frederic Z. Zhang},
year = {2024},
month = {Mar},
address = {Canberra, Australia},
note = {Available at \url{https://openresearch-repository.anu.edu.au/items/2f2331b2-77d4-422a-8acd-093a8d894895}},
school = {College of engineering, computing and cybernatics, The Australian National University},
type = {PhD thesis}
}